Stochastic differential equations (SDE). What are the differences respect to the ordinary differential equations (ODE). Try to understand and explain in your own words why the Itô calculus has been introduced and what is the main intuition behind the Itô integral.
SDE vs ODE
An equation containing the derivatives of one ormore dependent variables, with respect to one or more independent variables, is said to be a differential equation. Solve a differential equation means to find the function g(x) (called solution or integral) that makes the expression identically satisfied.
A ordinary differential equation (ODE) is a mathematical expression within which we find an unknown function y(x) and its first derivative y'(x). A stochastic differential equation (SDE) is a differential equation in which one or more of the terms is a stochastic process, resulting in a solution which is also a stochastic process.
So:
A ordinary differential equation: dx(t)/dt = a(t)x(t) and x(0) = x0 When we take the ODE and assume that a(t) is not a deterministic parameter but rather a stochastic parameter, we get a stochastic differential equation.
Itô calculus and Itô integral
Itô calculus extends the methods of calculus to stochastic processes such as Brownian motion. It has important applications in mathematical finance and stochastic differential equations. The central concept is the Itô stochastic integral, a stochastic generalization of the Riemann–Stieltjes integral in analysis.
The Itô stochastic integral amounts to an integral with respect to a function which is not differentiable at any point and has infinite variation over every time interval.
The Geometric Brownian motion and its importance for applications. The Ornstein-Uhlenbeck / Vasicek models and the concept of mean reversion.
The Geometric Brownian motion
A geometric Brownian motion (GBM) (also known as exponential Brownian motion) is a continuous-time stochastic process in which the logarithm of the randomly varying quantity follows a Brownian motion(the random motion of particles suspended in a medium) with drift (the change of the average value of a stochastic (random) process).
A stochastic process St is said to follow a GBM if it satisfies the following stochastic differential equation (SDE):
dSt = μStdt + σSt dWt
Brownian motion is often used to explain the movement of time series variables, and in corporate finance the movement of asset prices. A common assumption for stock markets is that theyfollow Brownian motion, where asset prices are constantly changing often by random amounts
Ornstein-Uhlenbeck or Vasicek process
The Ornstein-Uhlenbeck or Vasicek process is a stochastic process which is stationary, Gaussian, and Markovian. Over time, the process tends to drift towards its long-term mean: such a process is called mean-reverting. The Vasicek process is the unique solution to the following stochastic differential equation:
dXt = k(p – Xt)dt + σdWt
When p = 0 we talk of Ornstein model. K is the “speed of reversion”: characterizes the velocity at which such trajectories will regroup around p in time
The Ornstein Uhlenbeck process is often used to model interest rates because of its mean reverting property. Mean reversion is the process that describes that when the short-rate Xt is high, it will tend to be pulled back towards the long-term average level; when the rate is low, it will have an upward drift towards the average level. In Vasicek’s model the short-rate is pulled to a mean level p at a rate of k. The mean reversion is governed by the stochastic term σdWt which is normally distributed.
An “analog” of the CLT for stochastic process: the Brownian motion as limit of random walk and the functional CLT (Donsker theorem). Explain the intuitive meaning of this result.
A (μ, σ) Brownian motion is the limiting case of random walk.
A particle moves ∆x to the left with probability 1−p.
It moves to the right with probability p after ∆t time.
Define: Xi = +1, if the ith move is to the right Xi = -1, if the ith move is to the left
Xiare independent with P[Xi = 1] = p = 1 – P[Xi = -1]
Assume n = t/∆t is an integer
Its position at time t is Y(t) = ∆x(X1 + X2 + … + Xn)
Recall E[Xi] = 2p – 1 Var[Xi] = 1 – (2p – 1)2
And E[Y(t)] = n(∆x)(2p – 1) Var[Y(t)] = n(∆x)(1 – (2p – 1)2) with ∆x = σ√∆t and p = [ 1 + (μ/σ) √∆t]/2
Thus, {Y(t), t≥0} converges to a (μ, σ) Brownian motion by the central limit theorem.
Brownian motion with zero drift is the limiting case of symmetric random walk by choosing μ = 0
Functional extension of the central limit theorem, the Donsker’s theorem.
Let X1 , X2 , X3 , … be a sequence of independent and identically distributed (i.i.d.) random variables with mean 0 and variance 1.
Let . The stochastic process S := ( Sn ) n ∈ N is known as a random walk.
Define the diffusively rescaled random walk (partial-sum process) by
t ∈ [0,1]
The central limit theorem asserts that W(n)(1) converges in distribution to a standard Gaussian random variable W(1) as n -> ∞ .
In its modern form, Donsker’s invariance principle states that: As random variables taking values in the Skorokhod space D [0,1] (The set of all càdlàg functions from E to M is often denoted by D(E,M) and is called Skorokhod space), the random function W(n) converges in distribution to a standard Brownian motion W := (W(t)) t ∈ [0,1] as n -> ∞
What is a Brownian diffusion process. History, importance, definition and applications.
Brownian motion
A stochastic process, defined on a common probability space (Ω, Σ, P) with the following properties:
Increments must be independent and stationary (Cause is a Lévy process)
Increments has the N(0,Δt) distribution
x0 = 0
Path must be continuous with probability 1 (Almost sure): P{ω ∈ Ω : X( . , ω) is continuous} = 1
Diffusion Processes
A continuous time stochastic process with(almost surely) continuous sample paths which has the Markov property (the conditional probability distribution of future states of the process depends only upon the present state, not on the sequence of events that preceded it.) is called a diffusion.
The simplest and most fundamental diffusion process is Brownian motion(The independent increments imply the Markov property).
Also called Wiener process, It is one of the best known Lévy processes (càdlàg stochastic processes with stationary independent increments) and occurs frequently in pure and applied mathematics, economics, quantitative finance, evolutionary biology, and physics.
Brownian motion was discovered by the biologist Robert Brown in 1827, who observed through a microscope the random swarming motion of pollen grains in water. The theory of Brownian motion was developed by Bachelier in his 1900 PhD Thesis and independently by Einstein in his 1905 paper which used Brownian motion to estimate Avogadro’s number and the size of molecules. Wiener in 1923 proved that there exists a version of BM with continuous paths.
General correlation coefficient for ranks and the most common indices that can be derived by it. Can you make some interesting example of computation of these correlation coefficients for ranks?
Ranks
Are the places that observation occupies in the sample order.
A rank correlation is any of several statistics that measure an ordinal association(the relationship between rankings of different ordinal variables or different rankings of the same variable). The “ranking” is the assignment of the ordering labels “first”, “second”, “third”, etc. to different observations of a particular variable.
A rank correlation coefficient measures the degree of similarity between two rankings, and can be used to assess the significance of the relation between them.
Kendall (1970) showed that his τ and Spearman’s ρ are particular cases of a general correlation coefficient Γ:
Suppose we have a set of n objects characterized by two properties x and y. To any pair of individuals, say i-th and j-th, one can assign x-score aij = -aij and y-score bij = -bij, so:
Example
Suppose that two experts order four wines called {a,b,c,d}. The first expert gives the following order: O1= [a,c,b,d], which corresponds to the following ranks R1 = [1,3,2,4]. The second expert orders the wines as O2 = [a,c,d,b] which corresponds to the following ranks R2 = [1,4,2,3]. The order given by the first expertis composed of the following 6 ordered pairs:
P1 = {[a,c], [a,b], [a,d], [c,b], [c,d], [b,d]}
The order given by the second expert is composed of the following6 ordered pairs
P2 = {[a,c], [a,b], [a,d], [c,b], [c,d], [d,b]}
The set of pairs which are in only one set of ordered pairs is
{[b,d] [d,b]}
which gives a value of d∆(P1,P2) = 2 . With this value of the symmetric difference distance we compute the value of the Kendall rank correlation coefficient between the order given by these two experts as:
This large value of τ indicates that the two experts strongly agree on their evaluation of the wines (in fact their agree about everything but one pair).
Distributions of the order statistics: look on the web for the most simple (but still rigorous) and clear derivations of the distributions, explaining in your own words the methods used.
Order statistics
Pdf of the order statistics for a sample of size n = 5 from an exponential distribution with unit scale parameter
In statistics, the kth order statistic of a statistical sample is equal to its kth-smallest value. It is among the most fundamental tools in non-parametric statistics and inference(With ranks).
Important special cases of the order statistics are the minimum and maximum value of a sample, and the sample median. The sample median is a particular quantine: q is equal two, so the distribution is split into two part with the same frequencies.
If we have empirical sample, so, we can order it and find the order empirical sample:
Empirical sample
X1,X2,…,Xn
Empirical ordered sample
x(1),x(2),…,x(n)
X(k) means that is the k-th smallest value.
Note: In the case where the distribution F is continuous, we can make the stronger statement that x(1) < x(2) < x(3) < x(4) < x(5)
ProbabilityDensity
The PDF, by definition, for X(k) is:
So we can find easily:
Density for the FIRST ordinate statistic:
P{x(1) ∈ (x, x+dx)} = P(one of the X’s ∈ (x, x + dx) and all others > x) = they are iid => nf(x)dx (1 − F(x))n−1 with:
nf(x)dx from definition of the density (P{one of the X’s ∈ (x, x + dx)})
(1 − F(x))n−1 (P{all others n-1 obs > x + dx }) -> note that is the complement of the CDF
Density for theMAX order statistic:
P{x(n) ∈ (x, x+dx)} = P(one of the X’s ∈ (x, x + dx) and all others < x) = they are iid => nf(x)dx F(x)n−1 with:
nf(x)dx from definition of the density (P{one of the X’s ∈ (x, x + dx)})
F(x)n−1 (P{all others n-1 obs < x + dx }) -> note that is the CDF
Density for GENERAL case:
We must calculate density for the general case: this is a combinatory problem. (We have different way to distribute the observation in both side)
P{x(k) ∈ (x , x + dx)} =P(one of the X’s ∈ (x, x + dx) and exactly k−1 of the others < x):
Note that this looks like the Beta Distribution(r,s).
We have the binomial coefficient because we must choose k-1 elements from n-1 elements.
History and derivation of the normal distribution. Touch, at least, the following three perspectives, putting them into an historical context to understand how the idea developed and trying to understand the different derivations:
1) as approximation of binomial (De Moivre) 2) as error curve (Gauss) 3) as limit of sum of independent r.v.’s (Laplace)
The Normal Distribution
Mathematician Jakob Bernoulli, in a proof published in 1713, determined that the probability of k such outcomes in n repetitions is equal to the kth term (where k starts with 0) in the expansion of the binomial expression (p + q)n, where q = 1 − p.
So, the binomial distribution could be used to solve problems such as “If a fair coin is flipped 100 times, what is the probability of getting 60 or more heads?” The probability of exactly x heads out of N flips is computed using the formula:
where x is the number of heads (60), N is the number of flips (100), and p is the probability of a head (0.5). Therefore, to solve this problem, you compute the probability of 60 heads, then the probability of 61 heads, 62 heads, etc., and add up all these probabilities.
The importance of the normal curve stems primarily from the fact that the distributions of many natural phenomena are at least approximately normally distributed.
Abraham de Moivre, an 18th century statistician and consultant to gamblers, noted that when the number of events (coin flips) increased, the shape of the binomial distribution approached a very smooth curve:
de Moivre reasoned that if he could find a mathematical expression for this curve, he would be able to solve problems such as finding the probability of 60 or more heads out of 100 coin flips much more easily. This is exactly what he did, and the curve he discovered is now called the “normal curve.”
One of the first applications of the normal distribution was to the analysis of errors of measurement made in astronomical observations, errors that occurred because of imperfect instruments and imperfect observers. Galileo in the 17th century noted that these errors were symmetric and that small errors occurred more frequently than large errors and only in the early 19th century that it was discovered that these errors followed a normal distribution.
Independently, the mathematicians Adrain in 1808 and Gauss in 1809 developed the formula for the normal distribution and showed that errors were fit well by this distribution.
This same distribution had been discovered by Laplace in 1778 when he derived the extremely important central limit theorem. Laplace showed that even if a distribution is not normally distributed, the means of repeated samples from the distribution would be very nearly normally distributed, and that the larger the sample size, the closer the distribution of means would be to a normal distribution.
So, why does this distribution has the shape it has?
De Moivre
The limiting distribution of the binomial distribution. De Moivre was the first to approximate the factorial for large n and using this approximation, which is valid for large numbers, de Moivre went on to approximate the discrete binomial expansion with a continuous curve.
Gauss
In 1809, Gauss, developed this curve as the distribution of measurement errors. In order to derive de Moivre’s curve as the distributions for errors, Gauss made three assumptions
that errors are distributed symmetrically around a maximum value
that the value goes to zero for large positive and negative values of x
that the mean value of errors is the average value, namely zero
only the normal distribution satisfies these properties.
Laplace
In Laplace’s hands, this tendency for the curve to peak around a maximum at the mean value in the limit of large numbers came to be called the central limit theorem. He proved that, if xn ~ Bin(n,p) then:
Φ(x) be the probability density function of the random error
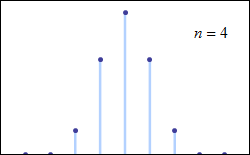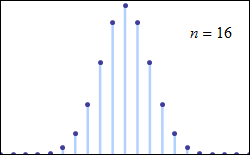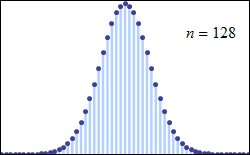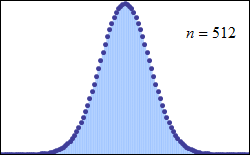
1) illustrates with visual evidence the law of large numbers LLN, and the various definitions of convergence 2) illustrates the binomial distribution 3) illustrates the convergence of the binomial to the normal 4) illustrates the central limit theorem 5) provides a basic example of stochastic process (sequence of r.v.’s defined on the same probability space)
LLN–Law of large numbers
Is a theorem that describes the result of performing the same experiment a large number of times. According to the law, the average of the results obtained from a large number of trials should be close to the expected value and will tend to become closer to the expected value as more trials are performed.
The expected value of a random variable , denoted ,is a generalization of the weighted average and is intuitively the arithmetic mean of a large number of independentrealizations of .
the expected value of a constant random variable is
the expected value of a random variable with equiprobable outcomes is defined as the arithmetic mean of the terms
If some of the probabilities of an individual outcome are unequal, then the expected value is defined to be the probability-weighted average of the , that is, the sum of the products . The expected value of a general random variable involves integration in the sense of Lebesgue.
The LLN is important because it guarantees stable long-term results for the averages of some random events.
While a casino may lose money in a single spin of the roulette wheel, its earnings will tend towards a predictable percentage over a large number of spins. Any winning streak by a player will eventually be overcome by the parameters of the game.
It is important to remember that the law only applies (as the name indicates) when a large number of observations is considered. There is no principle that a small number of observations will coincide with the expected value or that a streak of one value will immediately be “balanced” by the others. (The gambler’s fallacy, also known as the Monte Carlo fallacy, is the erroneous belief that if a particular event occurs more frequently than normal during the past it is less likely to happen in the future (or vice versa), when it has otherwise been established that the probability of such events does not depend on what has happened in the past.)
In the repeated toss of a fair coin, the outcomes in different tosses are statistically independent and the probability of getting heads on a single toss is 1/2. Since the probability of a run of five successive heads is 1/32, a person might believe that the next flip would be more likely to come up tails rather than heads again. This is incorrect and is an example of the gambler’s fallacy. The event “5 heads in a row” and the event “first 4 heads, then a tails” are equally likely, each having probability 1/32. Since the first four tosses turn up heads, the probability that the next toss is a head is: .
Simulation of coin tosses: Each frame, a coin is flipped which is red on one side and blue on the other. The result of each flip is added as a coloured dot in the corresponding column. As the pie chart shows, the proportion of red versus blue approaches 50-50 (the law of large numbers). But the difference between red and blue does not systematically decrease to zero.
Convergence concepts in probability
Converge in distribution
The r.v.s Xn converge in distribution to r.v. X if
Converge in distribution
Converge in probability
The r.v.s Xn converge in probability to r.v. X if for all ε > 0
Converge in probability
Converges almost surely
The r.v.s Xn converge in almost surely to r.v. X if
Converge almost surely
If Xn converges almost surely to X, then it also converges in probability. If Xn converges in probability to X, then it also converges in distribution.
The binomial distribution
A binomial distribution is a type of distribution that has two possible outcomes. Let p be the probability of success and q (=1−p) be the probability of failure. The binomial distribution is the probability distribution of the number x of successful trials in n Bernoulli trials and is denoted by Bi(n,p).
The binomial distribution is closely related to the Bernoulli distribution, the Bernoulli distribution is the Binomial distribution with n=1.
For example, a coin toss has only two possible outcomes: heads or tails and taking a test could have two possible outcomes: pass or fail.
The probability of having x successful trials is given by px, while the probability of having n−x unsuccessful trials is given by q(n−x). The number of combinations of x successful trials and n−x unsuccessful trials is given by
The binomial coefficient
The binomial distribution formula can calculate the probability of success for binomial distributions
Binomial distributions must also meet the following three criteria:
It starts at 0 because the first flip happened to be tails
The number of observations or trials is fixed. In other words, you can only figure out the probability of something happening if you do it a certain number of times. This is common sense—if you toss a coin once, your probability of getting a heads is 50%. If you toss a coin a 20 times, your probability of getting a heads is very, very close to 100%.
Each observation or trial is independent. In other words, none of your trials have an effect on the probability of the next trial.
The probability of success (tails, heads, fail or pass) is exactly the same from one trial to another.
The central limit theorem
The central limit theorem (CLT) establishes that, in many situations, when independent random variables are added, their properly normalized sum tends toward a normal distribution (informally a bell curve) even if the original variables themselves are not normally distributed.
A normaldistribution is a type of continuous probability distribution for a real-valued random variable.
If X1 , . . . , Xn are random samples each of size n taken from a population with overall mean μ and finite variance σ2 and if is the sample mean, the limiting form of the distribution of
as n → ∞ , is the standard normal distribution.
For example, suppose that a sample is obtained containing many observations, each observation being randomly generated in a way that does not depend on the values of the other observations, and that the arithmetic mean of the observed values is computed. If this procedure is performed many times, the central limit theorem says that the probability distribution of the average will closely approximate a normal distribution. A simple example of this is that if one flips a coin many times, the probability of getting a given number of heads will approach a normal distribution, with the mean equal to half the total number of flips. At the limit of an infinite number of flips, it will equal a normal distribution.
The central limit theorem has several variants: one of this, the de Moivre–Laplace theorem, says that normal distribution may be used as an approximation to the binomial distribution.
The de Moivre–Laplace theorem, which is a special case of the central limit theorem, states that the normal distribution may be used as an approximation to the binomial distribution under certain conditions.
Consider a series of n independent trials, each resulting in one of two possible outcomes, a success with probability p (0 < p < 1) and failure with probability q = 1-p. Let Xn denote the number of successes in these n trials. Then the random variable(r.v.) Xn is said to have binomial distribution with parameters n and p, b(n,p).
So
The probability density(or mass) function (pdf) of Xn is given by:
with sum(pn(x) = 1) for x = 0,…,n
The mean and variance of the binomial r.v. Xn are given, respectively, by:
E[Xn] = μ = np
Var[Xn] = σ² = npq = np(1-p)
For sufficiently large n, the following random variable has a standard normal distribution:
That is:
The general form of Normal distribution probability density function is:
Notation: N(μ,σ²)
For a binomial distribution, as n grows large, for k in the neighborhood of np we can approximate:
Pdf of binomial converge to a normal. N(0,1)
in the sense that the ratio of the left-hand side to the right-hand side converges to 1 as n → ∞.
(The normal distribution is generally considered to be a pretty good approximation for the binomial distribution when np ≥ 5 and n(1 – p) ≥ 5)
Stochastic process
Also called random process, is a mathematical object usually defined as a family of random variables. Many stochastic processes can be represented by time series. However, a stochastic process is by nature continuous while a time series is a set of observations indexed by integers. A stochastic process may involve several related random variables. The term random function is also used to refer to a stochastic or random process, because a stochastic process can also be interpreted as a random element in a function space.
One of the simplest stochastic processes is the Bernoulli process(discrete-time stochastic process), which is a sequence of independent and identically distributed (iid) random variables, where each random variable takes either the value one or zero, say one with probability p and zero with probability 1 − p.
This process can be linked to repeatedly flipping a coin, where the probability of obtaining a head is p and its value is one, while the value of a tail is zero.In other words, a Bernoulli process is a sequence of iid Bernoulli random variables, where each coin flip is an example of a Bernoulli trial.
Do some practical examples where you explain how the elements of an abstract probability space relates to more concrete concepts when doing statistics.
Statistics is the discipline that concerns the collection, organization, analysis, interpretation and presentation of data. When data cannot be collected, statisticians collect data by developing specific experiment designs and survey samples.
A probability space or a probability triple ( Ω , F , P ) is a mathematical construct that provides a formal model of a random process or “experiment”. In order to provide a sensible model of probability, these elements must satisfy a number of axioms.
We have descriptive statistics and inferential statistics.
In inferential statistics we need the concept of probability to draw conclusions from data. Probability theory provides a mathematical structure for statistical inference. Once we make our best statistical guess about what the probability model is (what the rules are), based on looking backward, we can then use that probability model to predict the future. The purpose of statistics is to make inference about unknown quantities from samples of data.
So
Statistics is applied to situations in which we have questions that cannot be answered definitively, typically because of variation in data.
Probability is used to model the variation observed in the data. Statistical inference is concerned with using the observed data to help identify the true proba-bility distribution (or distributions) producing this variation and thus gain insightinto the answers to the questions of interest
Think and explain in your own words what is the role that probability plays in Statistics and the relation between “empirical” objects – such as the observed distribution and frequencies etc – and “theoretical” counterparts.
Probabilities are numbers that reflect the likelihood that a particular event will occur. A probability of 0 indicates that there is no chance that a particular event will occur, whereas a probability of 1 indicates that an event is certain to occur. While in descriptive statistics we have been taking in term of frequency a mean description of a well know population, in inferential statistics we need the concept of probability, because provide information about a small data selection, so you can use this information to infer something about the larger dataset from which it was taken.
Empirical and theoretical
The probability is an abstraction of frequencies. In inference we take an evidence(empirical distribution) and we want identify the shape more likely of the evidence. So the goal is find the ‘State of nature’ more likely that have generate my sample. The sample can come from a number of infinite population that have different caratteristics that define the theoretical model.
Objects in empirical and theoretical distribution.

 . The stochastic process S := ( Sn ) n ∈ N is known as a random walk.
. The stochastic process S := ( Sn ) n ∈ N is known as a random walk. 












 , denoted
, denoted ![E[X]](https://wikimedia.org/api/rest_v1/media/math/render/svg/e455a34363c03fc5df8208d8b81fa29e3cdd524e) , is a generalization of the weighted average and is intuitively the arithmetic mean of a large number of independentrealizations of
, is a generalization of the weighted average and is intuitively the arithmetic mean of a large number of independentrealizations of  is
is 
 is defined as the arithmetic mean of the terms
is defined as the arithmetic mean of the terms 
 of an individual outcome
of an individual outcome  are unequal, then the expected value is defined to be the probability-weighted average of the
are unequal, then the expected value is defined to be the probability-weighted average of the  products
products  . The expected value of a general random variable involves integration in the sense of Lebesgue.
. The expected value of a general random variable involves integration in the sense of Lebesgue. .
.









 is the sample mean, the limiting form of the distribution of
is the sample mean, the limiting form of the distribution of 







