Explain how parametric inference works and the main ideas of statistical induction, including the role of Bayes theorem and the different approach between “bayesian” and “frequentist”.
Inferential statistics
You have a population which is too large to study fully, so you use statistical techniques to estimate its properties from samples taken from that population.
So, in inferential statistics, we try to infer something about a population from data coming from a sample taken from it. We need the concept of probability.
Statistical inference is a particular frame of Statistical induction.
Induction is a method of reasoning in which the premises are viewed as supplying some evidence, but not full assurance, for the truth of the conclusion. Inductive reasoning is distinct from deductive reasoning, where the conclusion of a deductive argument is certain.
Parametric statistics is a branch of statistics which assumes that sample data comes from a population that can be adequately modeled by a probability distribution that has a fixed set of parameters.
Example:
The normal family of distributions all have the same general shape and are parameterized by mean and standard deviation. That means that if the mean and standard deviation are known and if the distribution is normal, the probability of any future observation lying in a given range is known.
Frequentist and bayesian approach
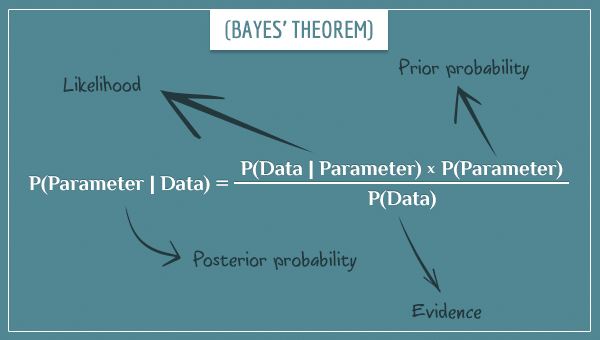
The problem is that we don’t know the prior probability. So, the inferential statistics splits in two:
- give it an uniform distribution
- give it a shape
The frequentist way
Sampling is infinite and decision rules can be sharp. Data are a repeatable random sample – there is a frequency. Underlying parameters are fixed i.e. they remain constant during this repeatable sampling process.
The Bayesian way
Unknown quantities are treated probabilistically and the state of the world can always be updated. Data are observed from the realised sample. Parameters are unknown and described probabilistically. It is the data which are fixed.
Are you a Bayesian or a Frequentist?
You have a coin that when flipped ends up head with probability p and ends up tail with probability 1−p. (The value of p is unknown.)
Trying to estimate p, you flip the coin 14 times. It ends up head 10 times.
Then you have to decide on the following event: “In the next two tosses we will get two heads in a row.”
Would you bet that the event will happen or that it will not happen?
Using frequentist statistics, we would say that the best (maximum likelihood) estimate for p is p=10/14.
In this case, the probability of two heads is 0.714
The Bayesian approach, instead, treat p as a random variable with its own distribution of possible values.
The distribution can be defined by the existing evidence. The logic goes as follows. What is the probability of a given value of p, given the data? We find it, with the Bayes thm.
https://www.behind-the-enemy-lines.com/2008/01/are-you-bayesian-or-frequentist-or.html
https://www.youtube.com/watch?v=TSkDZbGS94k
https://en.wikipedia.org/wiki/Confidence_interval
https://link.springer.com/chapter/10.1007/978-0-387-09612-4_9
https://en.wikipedia.org/wiki/Frequentist_inference
https://www.nasa.gov/consortium/FrequentistInference
https://en.wikipedia.org/wiki/Bayesian_inference
https://en.wikipedia.org/wiki/Parametric_statistics
https://en.wikipedia.org/wiki/Inductive_reasoning
https://stats.stackexchange.com/questions/22/bayesian-and-frequentist-reasoning-in-plain-english



 defines a metric.
defines a metric.




 and b
and b  , is the length of one side of a square whose area is equal to the area of a rectangle with sides of lengths
, is the length of one side of a square whose area is equal to the area of a rectangle with sides of lengths 























