Public Sub calc_regressionLineSecondOrder()
Dim s11 As Double
Dim s12 As Double
Dim s22 As Double
Dim sy1 As Double
Dim sy2 As Double
Dim N As Integer = listOfBDataP.Count
Dim sumX As Double
Dim sumX_X As Double
Dim sumPowX As Double
Dim sumProd As Double
Dim sumPowPow As Double
Dim sumXY As Double
Dim sumY As Double
Dim sumXYPow As Double
For Each x In listOfBDataP
sumX += x.x1
sumPowX += x.x1 * x.x1
sumProd += x.x1 * x.x1 * x.x1
sumPowPow += x.x1 * x.x1 * x.x1 * x.x1
sumXY += x.x1 * x.x2
sumY += x.x2
sumXYPow += x.x2 * x.x1 * x.x1
Next
sumX_X = sumX * sumX
s11 = sumPowX - (sumX_X / N)
s12 = sumProd - (sumX * sumPowX) / N
s22 = sumPowPow - (sumPowX * sumPowX) / N
sy1 = sumXY - (sumY * sumX) / N
sy2 = sumXYPow - (sumY * sumPowX) / N
Dim meanXPow As Double = sumPowX / N
b2 = (sy1 * s22 - sy2 * s12) / (s22 * s11 - s12 * s12)
b3 = (sy2 * s11 - sy1 * s12) / (s22 * s11 - s12 * s12)
b1 = current_onlineMeanY - b2 * current_onlineMeanX - b3 * meanXPow
End Sub
Simple variation of your application to simulate stochastic processes. Add to your previous program 13_A the following. Same scheme as previous program, except changing the way to compute the values at each time. Starting from value 0 at time 0, at each new time compute Y(i) = Y(i-1) + Random step(i). Where Random step(i) is a Rademacher random variable ( https://en.wikipedia.org/wiki/Rademacher_distribution ). At time n (last time) and one other chosen inner time 1<j<n (j is a program parameter) create and represent with histogram the distribution of Y(i).
Public Function Generate_randomWalk() As Path
…
Dim p As Double = 0.5
Dim v As Double = R.NextDouble
If v <= p Then
path.jump.Add(1)
else
path.jump.Add(-1)
End if
…
End Function
Simple illustration of the Glivenko-Cantelli theorem ( http://home.uchicago.edu/~amshaikh/webfiles/glivenko-cantelli_topics.pdf ). Consider random variables from a Uniform distribution (not necessarily in the same range), and create both the histogram and the empirical CDF of the sample mean. Show with an animation what happens when the number of observations increases. What do we see here?
We can see that as the number of observations increases, the empirical cdf closest to the real cdf and the histogram take a bell shape. The empirical CDF, infact, usually approximates the CDF quite well, especially for large samples.
Do a research about the random walk and its properties. Looking at your possible simulation in exercise 15_A, how would you describe the beaviour of the distribution of Y, as n increases ? What are mean and variance of Y at step n ?
The Random Walk
A random walk is a mathematical object, known as a stochastic or random process, that describes a path that consists of a succession of random steps on some mathematical space such as the integers.
More in general, a random walk refers to any process in which there is no observable pattern or trend; that is, where the movements of an object, or the values taken by a certain variable, are completely random. Certain real-life scenarios that could be modeled as random walks could be:
The movements of an animal foraging for food in the wilderness
The path traced by a molecule as it moves through a liquid or a gas (diffusion)
The price of a stock as it moves up and down
The path of a drunkard wandering through Greenwich Village
The financial status of a gambler at the roulette wheel in Las Vegas
A Fun Caveat on Random Walks: Monkeys and Typewriters
As n (steps) gets larger, we expect to get further and further from the origin. In fact, for an infinite number of random walks with an infinitely large number of steps, we will end up visiting every number on the number line.
This idea was illustrated quite vividly and humorously in the book Fooled by Randomness., by Nassim Nicholas Taleb In that book, Taleb posits the idea that:
if a sufficiently large group of monkeys were to type randomly on typewriters (a more complex variety of a random walk) for an infinite amount of time, one of those monkeys would necessarily compose The Iliad. And not only that—given infinite time, one of the monkeys who composes the Iliad will then go on to compose the Odyssey.
Distribution
The mean of the empirical distribution is an unbiased estimator (is the difference between this estimator’s expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased) of the mean of the population distribution.
When n increase, the mean is closer to the real value of theorical CDF.
The variance of the empirical distribution times n/n − 1 is an unbiased estimator of the variance of the population distribution.
History and derivation of the normal distribution. Touch, at least, the following three perspectives, putting them into an historical context to understand how the idea developed and trying to understand the different derivations:
1) as approximation of binomial (De Moivre) 2) as error curve (Gauss) 3) as limit of sum of independent r.v.’s (Laplace)
The Normal Distribution
Mathematician Jakob Bernoulli, in a proof published in 1713, determined that the probability of k such outcomes in n repetitions is equal to the kth term (where k starts with 0) in the expansion of the binomial expression (p + q)n, where q = 1 − p.
So, the binomial distribution could be used to solve problems such as “If a fair coin is flipped 100 times, what is the probability of getting 60 or more heads?” The probability of exactly x heads out of N flips is computed using the formula:
where x is the number of heads (60), N is the number of flips (100), and p is the probability of a head (0.5). Therefore, to solve this problem, you compute the probability of 60 heads, then the probability of 61 heads, 62 heads, etc., and add up all these probabilities.
The importance of the normal curve stems primarily from the fact that the distributions of many natural phenomena are at least approximately normally distributed.
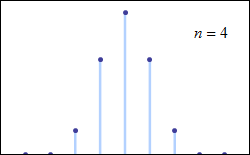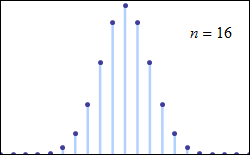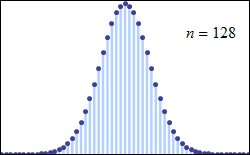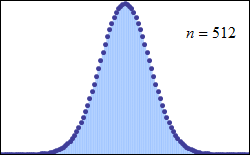
Abraham de Moivre, an 18th century statistician and consultant to gamblers, noted that when the number of events (coin flips) increased, the shape of the binomial distribution approached a very smooth curve:
de Moivre reasoned that if he could find a mathematical expression for this curve, he would be able to solve problems such as finding the probability of 60 or more heads out of 100 coin flips much more easily. This is exactly what he did, and the curve he discovered is now called the “normal curve.”
One of the first applications of the normal distribution was to the analysis of errors of measurement made in astronomical observations, errors that occurred because of imperfect instruments and imperfect observers. Galileo in the 17th century noted that these errors were symmetric and that small errors occurred more frequently than large errors and only in the early 19th century that it was discovered that these errors followed a normal distribution.
Independently, the mathematicians Adrain in 1808 and Gauss in 1809 developed the formula for the normal distribution and showed that errors were fit well by this distribution.
This same distribution had been discovered by Laplace in 1778 when he derived the extremely important central limit theorem. Laplace showed that even if a distribution is not normally distributed, the means of repeated samples from the distribution would be very nearly normally distributed, and that the larger the sample size, the closer the distribution of means would be to a normal distribution.
So, why does this distribution has the shape it has?
De Moivre
The limiting distribution of the binomial distribution. De Moivre was the first to approximate the factorial for large n and using this approximation, which is valid for large numbers, de Moivre went on to approximate the discrete binomial expansion with a continuous curve.
Gauss
In 1809, Gauss, developed this curve as the distribution of measurement errors. In order to derive de Moivre’s curve as the distributions for errors, Gauss made three assumptions
that errors are distributed symmetrically around a maximum value
that the value goes to zero for large positive and negative values of x
that the mean value of errors is the average value, namely zero
only the normal distribution satisfies these properties.
Laplace
In Laplace’s hands, this tendency for the curve to peak around a maximum at the mean value in the limit of large numbers came to be called the central limit theorem. He proved that, if xn ~ Bin(n,p) then:
Φ(x) be the probability density function of the random error